Running SOTA Whole-Body Pose Estimation with a single command
- Namas Bhandari
- Mar 16
- 3 min read


If you've worked with pose estimation models from MMPose, you know the drill - clone the repo, install PyTorch, install mmcv, install mmpose, pray that the CUDA versions align, and then figure out the config system. For deployment or quick prototyping, that's way too much friction.
I went through the same thing with CIGPose, a recent pose estimator that uses causal intervention to handle occlusion better than anything else out there right now (67.5 Whole AP on COCO-WholeBody). Great model, but running it meant pulling in the entire MMPose stack and figuring out inference.
So I exported all 14 model variants to ONNX and wrote a single inference script that only needs onnxruntime, opencv, and numpy. No PyTorch, no MMPose, no config files.
What makes CIGPose different?
Most pose estimators learn spurious correlations from visual context. If a hand is near a table, the model might predict the hand is on the table even when it's not. CIGPose formalizes this using a Structural Causal Model (SCM) where visual context is treated as a confounder creating a backdoor path between image features and pose predictions.
The fix is a Causal Intervention Module (CIM) that:
1. Measures predictive uncertainty across keypoint embeddings to figure out which ones are "confused" by context.
2. Swaps those confused embeddings for learned, context-invariant canonical embeddings.
On top of that, a Hierarchical Graph Neural Network enforces anatomical plausibility - local message passing within body parts (intra-part) and global message passing across the full skeleton (inter-part). This stops the model from predicting physically impossible poses.
The Pipeline
Standard top-down approach:
1. YOLOX-Nano (or any other detector) detects person bounding boxes (Apache 2.0, 3.5 MB)
2. Each person is cropped with 1.25x padding, aspect-ratio corrected, resized to model input, and normalized with ImageNet stats
3. CIGPose runs SimCC coordinate classification - instead of predicting heatmaps, it predicts 1D distributions along X and Y axes for each keypoint
4. Decoding is just argmax for position and raw logit peak for confidence (matching MMPose's get_simcc_maximum)
5. Coordinates are remapped back to the original frame
Embedding metadata in ONNX
One thing I wanted to avoid was shipping config files alongside the models. Each CIGPose variant has different input sizes (256x192 or 384x288), split ratios, and keypoint counts (133, 17, or 14). Instead of sidecar JSON/YAML files, I embedded all of this directly into the ONNX model's metadata properties during export:

At inference time, the script reads this back from the ONNX session:

Pick any of the 14 ONNX files and the script auto-configures itself. It also auto-selects the right skeleton visualization (COCO-WholeBody 133, COCO 17, or CrowdPose 14) based on the keypoint count.
YOLOX grid decoding
For a filler, I used YOLOX nano as the detector model to get the detection boxes for top-down pose estimation. One gotcha worth mentioning - YOLOX-Nano's raw ONNX output is not pre-decoded. The output shape is [1, 3549, 85] where 3549 comes from three feature map strides (8, 16, 32) on a 416x416 input: 52x52 + 26x26 + 13x13.
The cx/cy values are relative to grid cells and w/h are log-scale. You need to apply grid offsets and stride multiplication before you get usable bounding boxes:
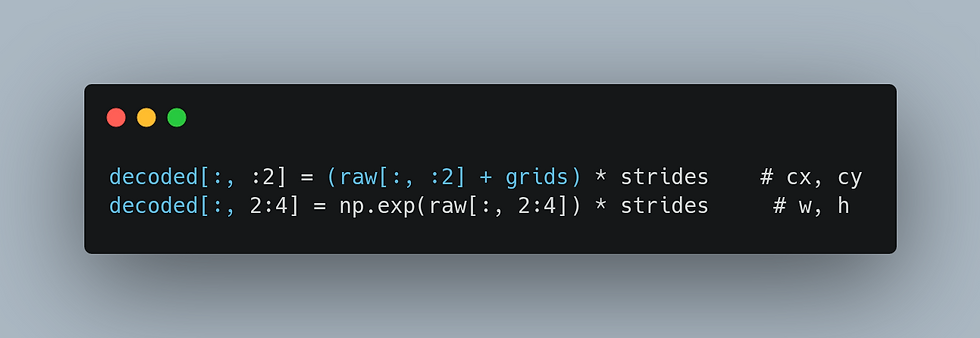
Skip this and you'll get 2-pixel bounding boxes that look like the detector isn't working at all.
Running it

There are 14 models across three datasets - COCO-WholeBody (133 kpts), COCO body (17 kpts), and CrowdPose (14 kpts).
Swapping the detector
YOLOX-Nano is tiny (3.5 MB) and good enough for most cases, but if you need better detection accuracy you can drop in any YOLOX variant (Tiny/S/M/L/X) - the YOLOXDetector class handles all of them. Or implement your own detector with a detect(frame) method that returns [x1, y1, x2, y2] boxes.
One thing to watch out for: Ultralytics YOLO is AGPL-3.0, so if licensing matters to you, stick with YOLOX (Apache 2.0) or RT-DETR.
--
Big thanks to https://github.com/53mins for CIGPose - all the model architectures, training, and weights are their work. This repo is just the ONNX plumbing to make it easier to use.



Comments